LongCat-2.0: El Sigiloso Modelo de IA Que Estuvo Liderando OpenRouter en Silencio Todo Este Tiempo

En Resumen
- Meituan reveló que LongCat-2.0 operó dos meses en OpenRouter bajo el alias Owl Alpha antes de su lanzamiento oficial.
- El modelo obtuvo 59,5 en SWE-bench Pro, superando el 58,6 de GPT-5.5 y el 54,2 de Gemini 3.1 Pro en código.
- Su API cuesta $0,75/$2,95 por millón de tokens, muy por debajo de los $5/$30 de GPT-5.5 y $2/$10 de Sonnet 5.
La empresa tecnológica china Meituan presentó oficialmente LongCat-2.0 el 30 de junio, confirmando que el modelo de IA de mezcla de expertos de 1,6 billones de parámetros con licencia abierta es el mismo sistema que pasó dos meses funcionando de forma anónima en OpenRouter bajo el alias Owl Alpha.
Los parámetros son el número total de variables que un modelo puede manejar durante el entrenamiento. El modelo activa aproximadamente 48.000 millones de sus parámetros por token (la unidad más pequeña de datos que procesa un modelo de IA), con esa cifra oscilando entre 33.000 millones y 56.000 millones dependiendo de lo exigente que sea la consulta.
El período de sigilo dio sus frutos. Para cuando Meituan dio la cara, el modelo ya había alcanzado el primer lugar en el workspace de Hermes Agent, el segundo en Claude Code y el tercero en los despliegues de OpenClaw, todos clasificados por volumen de llamadas mensual.
Este es el primer modelo de un billón de parámetros entrenado y desplegado de principio a fin en ASICs domésticos chinos, no solo servido en ellos después de entrenarse en otro lugar. En comparación, el V4-Pro de DeepSeek utilizó chips de Huawei solo para inferencia, mientras que el preentrenamiento se realizó en hardware de Nvidia.
Meituan afirma que la ejecución de preentrenamiento, que abarcó más de 35 billones de tokens en un clúster de más de 50.000 aceleradores de producción nacional, finalizó “sin retrocesos ni picos de pérdida irrecuperables”. Esa afirmación de estabilidad es relevante dado lo frecuente que es que las grandes ejecuciones de entrenamiento en stacks de hardware no probados fallen a mitad de camino, y cómo China parece estar reduciendo su dependencia del hardware estadounidense para entrenar sus modelos.
El precio es donde LongCat-2.0 presenta su argumento más sólido. El acceso estándar a la API cuesta $0,75 por millón de tokens de entrada y $2,95 por millón de salida, reducido a $0,30/$1,20 durante la promoción de lanzamiento actual, con lecturas de contexto en caché sin costo. Eso queda por debajo de los $5/$30 por millón de tokens de GPT-5.5, la tarifa introductoria de $2/$10 de Claude Sonnet 5, y se ubica cerca de los $0,435/$0,87 permanentes de DeepSeek V4-Pro y del MiMo-V2.5 Pro de Xiaomi, que igualó esa misma tarifa tras sus propios recortes de precios en mayo.
Meituan también ofrece un plan de tokens, que abarata aún más las cosas para desarrolladores y usuarios intensivos, con paquetes de 1.000 millones de tokens por alrededor de $60.
Pusimos a prueba LongCat-2.0 con una prueba rápida de creación de juegos. Cumplió con el objetivo y el resultado se mantuvo razonablemente bien tras algunas rondas de iteración. El resultado quedó visiblemente por detrás de Claude Fable y Opus 4.8, ubicándolo más cerca de Sonnet 4.6, pero la relación calidad-precio es difícil de discutir a estos precios.
Logró que las oleadas de enemigos llegaran desde diferentes ángulos con la cámara centrándose automáticamente en el enemigo más cercano. Sin embargo, la lógica del modelo no tomó en cuenta lo que sucede cuando el número de enemigos aumenta con la dificultad. A velocidades más altas, la lógica de cambio de objetivo se volvía errática; el enfoque saltaba a un enemigo más cercano en medio de un prompt de escritura, haciendo el juego frustrantemente injugable.
Esto es normal en sesiones de vibe coding, donde los modelos no prevén muchas consecuencias lógicas de una decisión y en su lugar se concentran en entregar un resultado basado en lo que el usuario solicita, literalmente.
Esta es también la razón por la que un modelo barato siempre es una buena opción, porque le da al usuario más oportunidades de mejorar iterativamente cada resultado hasta que el producto final cumpla con las expectativas.
En todo caso, sin mayor interacción, a primera vista la calidad general se ubica en algún punto entre DeepSeek v4 Flash y DeepSeek v4 Pro en nuestras pruebas rápidas de programación.
Puedes ver los resultados en nuestro sitio de itch.io
Cómo lo Construyó Meituan
LongCat-2.0 utiliza varias técnicas para hacer el modelo más rápido y capaz sin aumentar drásticamente su tamaño.
Su sistema de atención, basado en el diseño de DeepSeek, se enfoca únicamente en las partes más relevantes de conversaciones muy largas en lugar de procesar todo por igual, ayudándolo a responder más rápidamente.
Además, un nuevo sistema de embedding de N-gramas (una forma de ayudar a comprender grupos de palabras o subpalabras juntas) le da al modelo una comprensión mucho más rica de palabras y frases —aproximadamente 100 veces más representaciones posibles— sin agregar muchos más componentes de IA. Básicamente, le enseña a la IA a reconocer frases comunes en lugar de solo palabras individuales. En vez de ver “New”, “York” y “City” como tres piezas separadas, también puede tratar “New York City” como un solo concepto significativo. Esto le da al modelo una comprensión mucho más rica del lenguaje sin hacerlo dramáticamente más grande.
Después del entrenamiento, Meituan también combina tres sistemas especializados: uno enfocado en el uso de herramientas (Agent), otro en la resolución de problemas (Reasoning) y otro en conversaciones (Interaction). Un mecanismo de enrutamiento decide entonces qué combinación de esos especialistas debe encargarse de cada solicitud, de forma similar a asignar el equipo correcto al trabajo correcto.
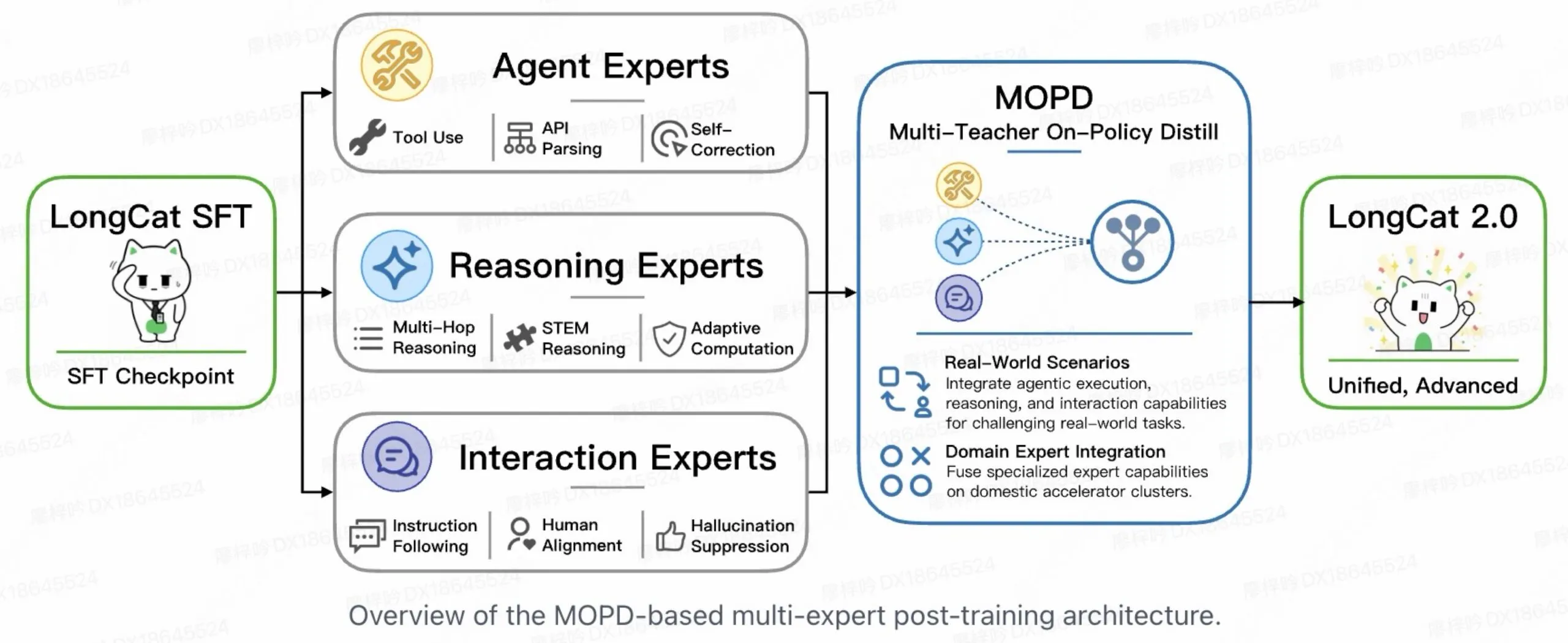
En SWE-bench Pro, un benchmark que evalúa con qué frecuencia un modelo resuelve issues reales de GitHub extraídos de bases de código en producción, LongCat-2.0 obtuvo 59,5, por encima del 58,6 de GPT-5.5 y del 54,2 de Gemini 3.1 Pro, aunque todavía por detrás de Claude Opus 4.7 y 4.8. En FORTE, que califica agentes en tareas de oficina cotidianas en 15 profesiones bajo un límite de 45 minutos, obtuvo 73,2, empatado con Claude Opus 4.6 pero por detrás del 77,8 de GPT-5.5.
Introducing LongCat-2.0
1.6T parameters · MoE with ~48B active · 1M context
The full model behind Owl Alpha on @OpenRouter — now available.Built for agentic coding from the ground up:
◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
◆… pic.twitter.com/zum2SdZ0Z2— Meituan LongCat (@Meituan_LongCat) June 30, 2026
Los equipos que construyen agentes de programación con presupuesto limitado, o cualquiera que ejecute trabajo a gran escala en repositorios donde las lecturas gratuitas de caché de contexto se acumulan, obtienen la ventaja más clara. El modelo está disponible hoy a través de los endpoints de API compatibles con OpenAI y Anthropic de Meituan, o a través de arneses de agentes como Hermes, Claude Code y OpenClaw que ya lo integran.
Quien necesite alojarlo por cuenta propia no tiene suerte por ahora. Tanto los repositorios de GitHub como los de Hugging Face todavía muestran “pesos del modelo próximamente”, pero Meituan no ha establecido una fecha para cuándo estarán disponibles los archivos.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.
Crédito: Enlace fuente




Responses